Proofs and Essays Are Paths: An LLM ↔ Prover Loop for Falsifying Hallucinations
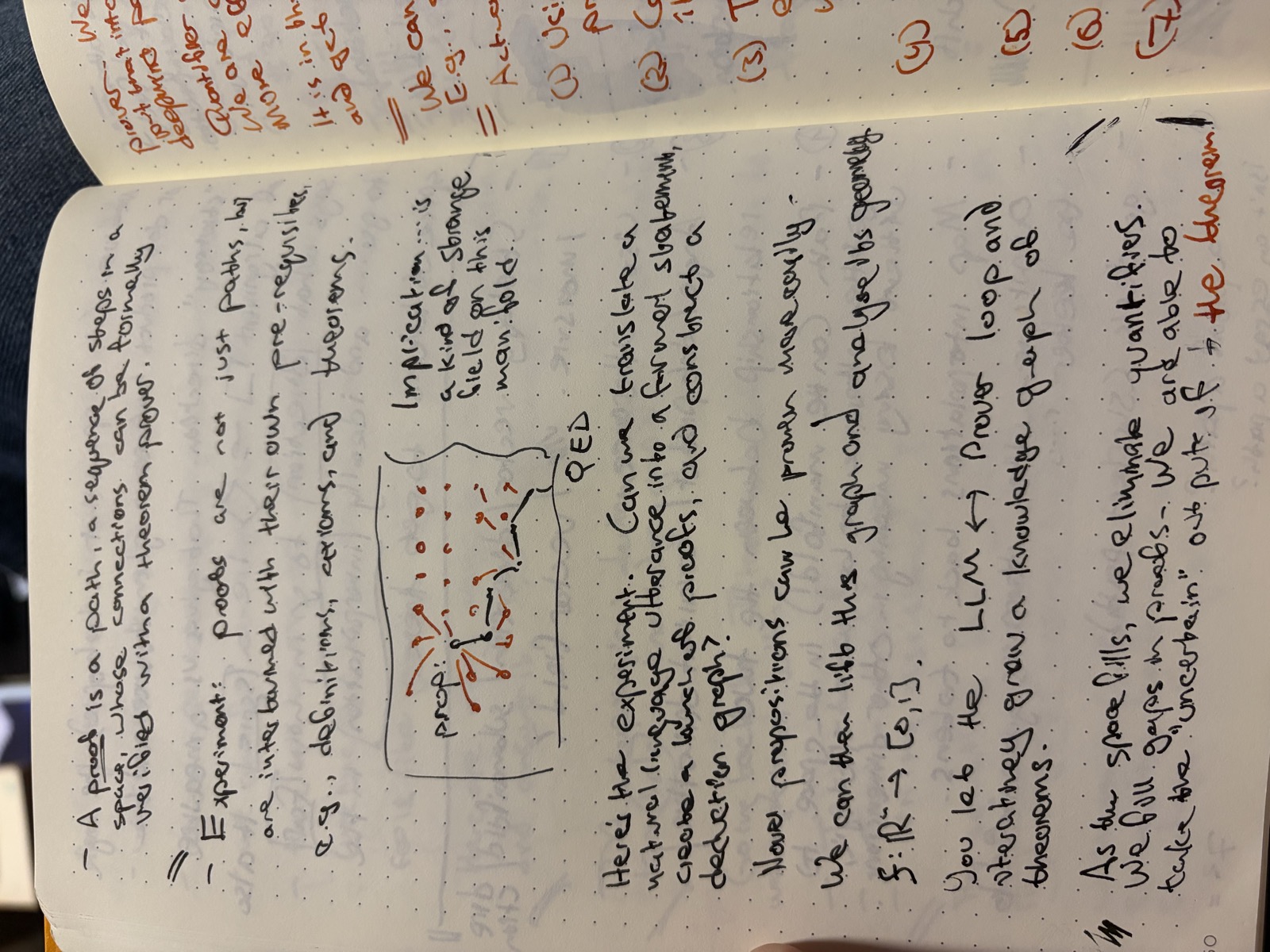
The visual on this page is the whole post. Propositions as nodes; implications and equivalences as edges; “QED” at the bottom of a graph that’s filling itself in. The chatbot’s job stops being “sample the next token” and becomes “extend the graph.”
Why this post exists
The April 2026 post I Was Thinking About LLM + Automated Reasoning Before It Was Cool describes the November 2023 sketch: feed LLM output to an SMT solver, eliminate quantifiers, return a verified answer. This post picks up the same thread four months later (March 2024), with two new pieces:
- The loop is bidirectional. LLM output → theorem-prover input and theorem-prover output → LLM input. AR is essentially first-order logic; we can quantize LLM outputs to binary-ish representations, feed them in, and back-propagate a “logical-learner” loss.
- Hallucinations are gaps in a path. A proof is a path through a space whose connections can be formally verified. An essay is the same shape but with looser verification. If we lift LLM-generated propositions into a knowledge graph of theorems, hallucinations show up as graph-paths whose edges fail to verify.
The thread
Logic as graphs, propositions as nodes
Sketch: each proposition is a graph node; each implication / equivalence is an edge. The LLM proposes nodes and edges; the theorem prover validates them. Over time the graph fills in.
The fact-checking ladder

Levels of difficulty for a single proposition:
- Is statement A true or false? Embed it; look for nearby contradictions.
- Is
A → Btrue? One-step implication. - Is
Γ(A, B)true for some relationΓ? Multi-step reasoning: induction, deduction, transduction, abduction.
The hard form is fact-checking with source attribution — surface-area / “1/φ” framing — which the notebook flags but doesn’t solve.
What changes when the loop closes
Rather than hallucinating the next LLM output, the chatbot should output an action — a construction in a reasoning space.
The chatbot becomes a knowledge-graph builder, not a token sampler. Each reply extends the graph with a new node and edges. When the graph has a hole, the model says so. When the proposed extension fails to verify, the model says so.
This is the abstract version of the argument I made concretely three weeks later in The Verification Problem: when AI-generated proofs are cheap and human verification is expensive, the only thing that scales is machine-checkable structure. This post sketches what the alternative would look like; that one shows what’s at stake when it doesn’t exist yet.
Connection to the geometry post
The companion post The Geometry of Language makes the same observation about essays: they are paths through embedding space, and “strategic-ness” is a direction. Together the two posts argue that the right way to think about LLM outputs is structural (path-finding) rather than stochastic (next-token).
Prior art the notebook flagged
The original page wrote “Lean / AlphaGeometry / NVIDIA” in the margin without citations. The work it was pointing at:
- Trinh, Wu, Le, He, Luong, Solving olympiad geometry without human demonstrations, Nature 625, 476–482 (doi:10.1038/s41586-023-06747-5, 17 January 2024). Google DeepMind’s AlphaGeometry — the system that pairs a symbolic deductive engine with a transformer language model and solves olympiad geometry problems near IMO gold-medalist level. This is the canonical example of the LLM ↔ prover loop the notebook was sketching.
- Yang, Swope, Gu, Chalamala, Song, Yu, Godil, Prenger, Anandkumar, LeanDojo: Theorem Proving with Retrieval-Augmented Language Models (arXiv:2306.15626, NeurIPS 2023). Caltech’s open framework for training and evaluating LLM theorem provers against the Lean proof assistant — provides the data infrastructure the AlphaGeometry-style loop needs to scale beyond geometry.
- DeepMind’s AlphaProof (2024) and DeepSeek-Prover-V2 (April 2025) are the more recent points on the same trajectory: both prove non-trivial mathematics in Lean 4 at competition level. The pattern they share with AlphaGeometry: a symbolic verifier holds the model accountable, not a softmax over likely next tokens.
“NVIDIA” in the margin probably referenced internal LLM-prover work I wasn’t tracking carefully at the time; if a reader knows the specific paper, I’d appreciate the pointer.
TODO before publish
- Build the toy: a tiny LLM ↔ Z3 loop on arithmetic propositions, with a knowledge graph that grows as the loop runs
- Run on a public benchmark — TAM AI’s hallucination eval, or something equivalent
- Cite Lean / AlphaGeometry / NVIDIA’s work — added AlphaGeometry (Nature 2024), LeanDojo (NeurIPS 2023), AlphaProof (2024), DeepSeek-Prover-V2 (2025); NVIDIA pointer flagged as open
- Decide: stays as a separate post from [The Geometry of Language] — the two argue the same shape (“paths > stochastic next-token”) to different prior-art communities (formal verification here, manifold learning there); merging would require either a post that pleases neither or one too long for either audience to finish. Cross-link via the “isn’t an essay a path? isn’t a proof a path?” hinge already in both.